
What Fable is
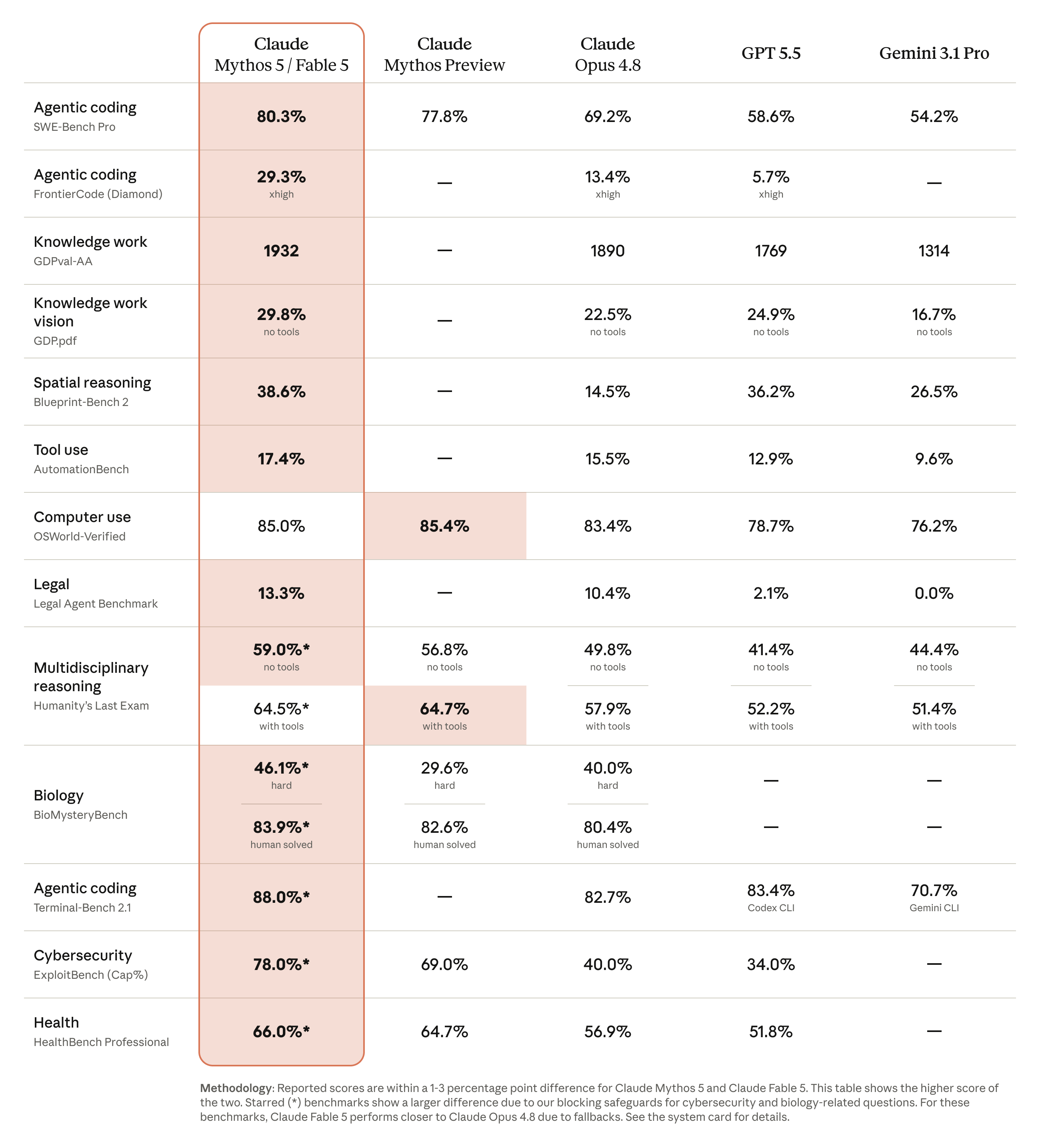
Fable 5 is Anthropic's most intelligent model — a new tier above Opus, the way Opus sits above Sonnet. Announced June 9, 2026, it is state-of-the-art on nearly every benchmark Anthropic tested, works autonomously for longer than any previous Claude, and is more token-efficient doing it.
It arrives with an unusual companion. Fable 5 is what Anthropic calls a Mythos-class model made safe for general use. Mythos 5 is the same underlying model with safeguards lifted in specific areas — restricted to vetted partners doing security and life-sciences research (Chapter VII). Fable is the version you and your API key can have.
| Property | Value |
|---|---|
| Model ID | claude-fable-5 — use this exact string; no date suffix |
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens (streaming required for large outputs) |
| Thinking | Adaptive only — the model decides when and how deeply to think |
| Structured outputs | Supported (output_config.format) |
| Vision | State-of-the-art, high-resolution image input |
It shares its API surface with Opus 4.7 and 4.8 — if your code runs on those, it runs on Fable with a one-line model swap, plus one new rule covered in Chapter V.
What it can do
Software engineering
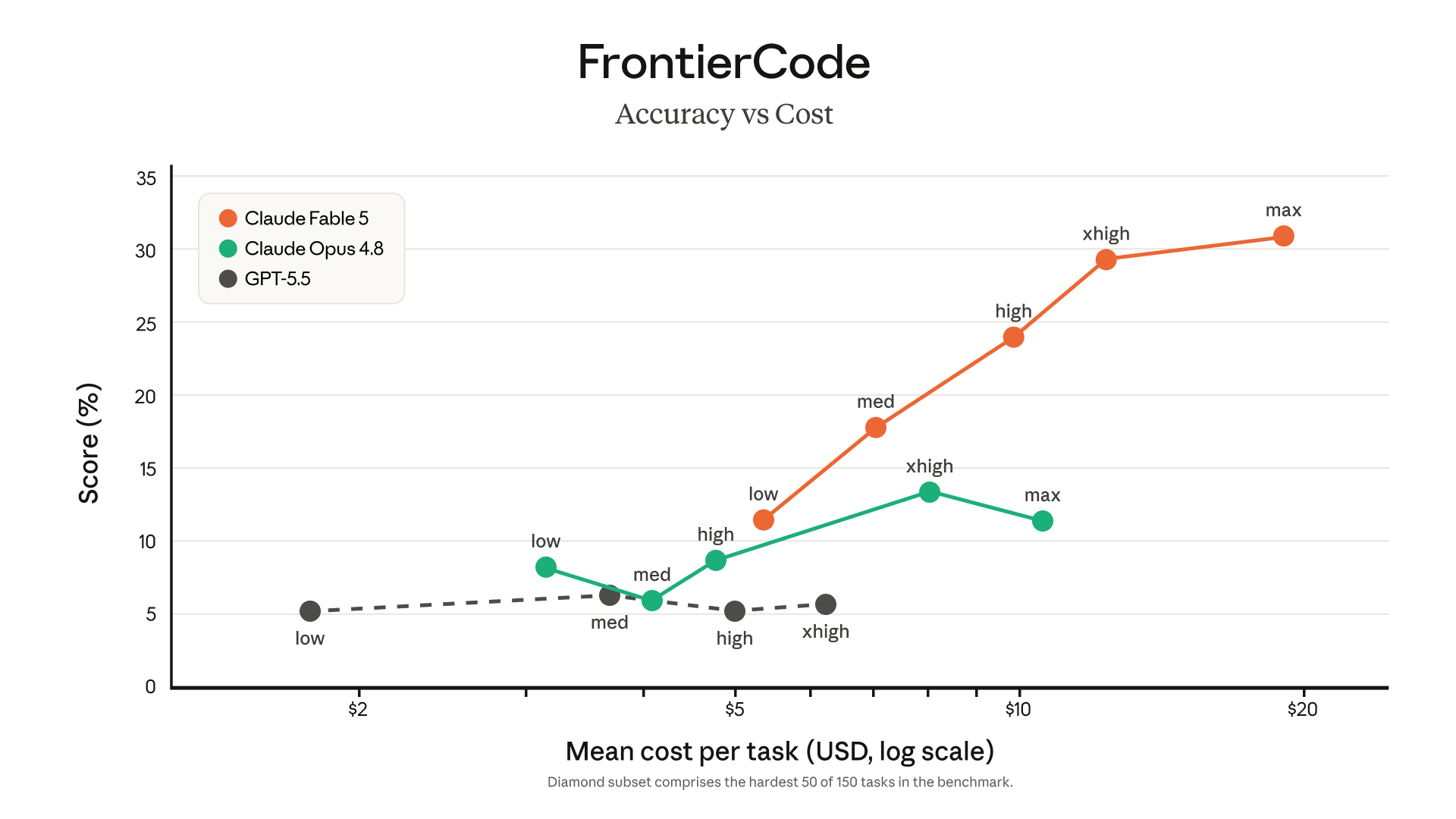
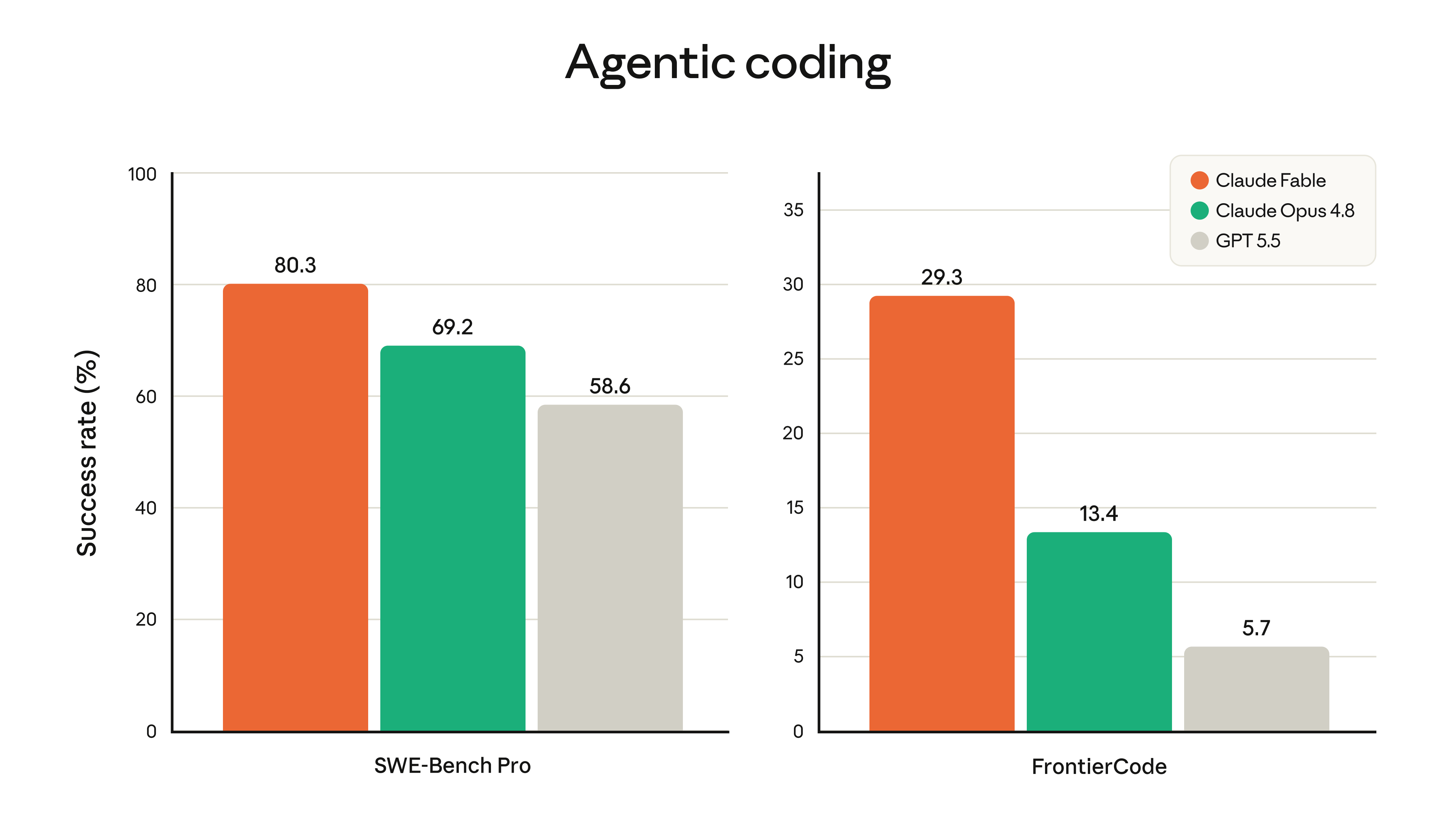
This is where the early stories are loudest. Stripe reported Fable 5 compressed months of engineering into days — including a 50-million-line Ruby codebase migration finished in one day that a team had scoped at two months. On Cognition's FrontierCode evaluation it posted the highest score among frontier models — at medium effort.
{kind=link}
"State of the art model on CursorBench. Opened up a class of long-horizon problems out of reach for earlier models."— Michael Truell, CEO & Co-founder, Cursor
"Took on complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks."— Mario Rodriguez, Chief Product Officer, GitHub
Knowledge work
Highest score on Hebbia's Finance Benchmark for senior-level reasoning — the first model to break 90% on their core analytics benchmark, a 10-point jump over Opus. Trading firm IMC said it "aced their trading-analysis evaluations nearly across the board." Strong document reasoning, chart and table interpretation throughout.
Vision
State-of-the-art on vision: it extracts precise numbers from dense scientific figures, rebuilds web-app source code from screenshots alone, and — the announcement's best party trick — completed Pokémon FireRed using vision only, with a minimal harness where previous models needed elaborate helper tooling.
Memory and long context
Fable stays focused across millions of tokens. Given persistent file-based memory in Slay the Spire, its performance improved 3× more than Opus 4.8's did, and it reached the game's final act 3× more often. The lesson for builders: give it a memory file — it actually uses one.
"Strongest model on frontier physics research while using a third of the reasoning tokens. In 36 hours it got nearly to where GPT-5.5 landed after four days."— Matthew Pines, CEO, Notation Capital
Where to get it, what it costs
The Claude API
Available everywhere as of June 9. On the API and consumption-based Enterprise it's fully available immediately. Pricing per million tokens — less than half the cost of the old Claude Mythos Preview:
| Model | ID | Input | Output |
|---|---|---|---|
| Claude Fable 5 | claude-fable-5 | $10.00 | $50.00 |
| Claude Opus 4.8 | claude-opus-4-8 | $5.00 | $25.00 |
| Claude Sonnet 4.6 | claude-sonnet-4-6 | $3.00 | $15.00 |
| Claude Haiku 4.5 | claude-haiku-4-5 | $1.00 | $5.00 |
Twice the price of Opus buys the highest intelligence ceiling Anthropic ships — and its token efficiency claws some of that back. Route your hardest problems to Fable; keep high-volume routine work on Sonnet or Haiku.
Subscription plans
Claude Code
Fable 5 powers Claude Code — terminal CLI, desktop app, web app, and IDE extensions. If you'd rather use Fable than call it, that's the shortest path. Anthropic's own CTO put it this way:
"Delivers more capable engineering in fewer turns than prior models — handling complex multi-agent workflows our employees run daily in Claude Code."— Luke Anderson, CTO, Anthropic
Your first call
One request, three choices made for you: adaptive thinking on, effort high, and room to answer.
curl
curl https://api.anthropic.com/v1/messages \
-H "content-type: application/json" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-fable-5",
"max_tokens": 16000,
"thinking": {"type": "adaptive"},
"output_config": {"effort": "high"},
"messages": [{"role": "user", "content": "Explain CRDTs like a fable."}]
}'Python
import anthropic
client = anthropic.Anthropic() # reads ANTHROPIC_API_KEY from the environment
response = client.messages.create(
model="claude-fable-5",
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={"effort": "high"},
messages=[{"role": "user", "content": "Explain CRDTs like a fable."}],
)
for block in response.content:
if block.type == "text":
print(block.text)For long outputs, stream — the SDKs refuse non-streaming requests they estimate will outlive the HTTP connection:
with client.messages.stream(
model="claude-fable-5",
max_tokens=64000,
thinking={"type": "adaptive"},
messages=[{"role": "user", "content": "Write the design doc."}],
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)The rules that changed
Fable follows the modern Claude API surface. If you're coming from older code, five things will bite — each is a clean 400 error, so you'll know.
| Old habit | On Fable 5 |
|---|---|
temperature, top_p, top_k | Removed — returns 400. Steer with prompting instead. |
thinking: {"type": "enabled", "budget_tokens": N} | Removed — use {"type": "adaptive"}; control depth with effort. |
thinking: {"type": "disabled"} | Fable-specific: an explicit disabled returns 400. To run without thinking, omit the thinking field entirely. |
| Assistant-turn prefills | Removed — use structured outputs (output_config.format) or a system-prompt instruction. |
Large max_tokens without streaming | Stream anything above ~16K output tokens. |
thinking: {"type": "adaptive", "display": "summarized"} — otherwise the long pause before output is the model thinking with nothing to show.Moral: don't tune the dials — state the task. Fable rewards a clear goal over a clever configuration.
Getting the most out of it
Pick an effort, then iterate
output_config.effort sets how hard Fable works — thinking depth, tool-call consolidation, and verbosity all scale with it. Five levels: low, medium, high (the default), xhigh, and max. Start at high; use xhigh for coding and agentic runs; reserve max for problems where correctness outweighs both cost and latency. Remember FrontierCode: Fable took the top score at medium — higher effort up front often lowers total cost on agentic work, because better planning means fewer turns.
Give it the whole task at once
Fable's long-horizon strength comes out when the full specification arrives in one well-written first turn — the goal, the constraints, and what "done" looks like. Drip-feeding requirements across turns wastes its planning; a complete brief lets one run carry the work end to end. That's how a 50-million-line migration fits in a day.
Give it a memory file
The Slay the Spire result generalizes: agents that keep notes outperform agents that don't, and Fable is markedly better than its predecessors at writing and using file-based memory. A scratchpad file and one line of system prompt ("check your memory file before starting; write new findings to it") is the cheapest capability upgrade available.
Structured outputs over parsing
response = client.messages.parse(
model="claude-fable-5",
max_tokens=16000,
messages=[{"role": "user", "content": document}],
output_format=ContactInfo, # a Pydantic model — validated for you
)
contact = response.parsed_outputCache your prefix
With a 1M-token window and $10/MTok input, prompt caching is not optional at scale. Mark the stable prefix with cache_control: {"type": "ephemeral"}; reads cost ~10% of base input price. Fable's minimum cacheable prefix is 2,048 tokens, and any byte change in the prefix invalidates everything after it — keep system prompts frozen and put volatile content last.
Budget long agentic runs
For autonomous loops, task budgets (beta header task-budgets-2026-03-13) give the model a token allowance it can see and self-pace against — output_config.task_budget: {"type": "tokens", "total": N}, minimum 20,000. Unlike max_tokens, the model is aware of it and wraps up gracefully as it runs down.
The wilder twin: Mythos 5 and the safeguards
Every fable has a creature too powerful to let loose. Anthropic's answer was to ship two versions of one model: Fable 5, guarded for everyone, and Mythos 5, unguarded in narrow domains for vetted researchers.
How Fable's safeguards work
Classifiers watch three areas — cybersecurity (vulnerability discovery, exploitation, offensive cyber tasks), biology & chemistry (bioweapons-adjacent queries), and distillation (attempts to extract the model for training competitors). They trigger on less than 5% of sessions on average. When one trips, the response is handled by Claude Opus 4.8 instead — so 95%+ of sessions never see a fallback at all.
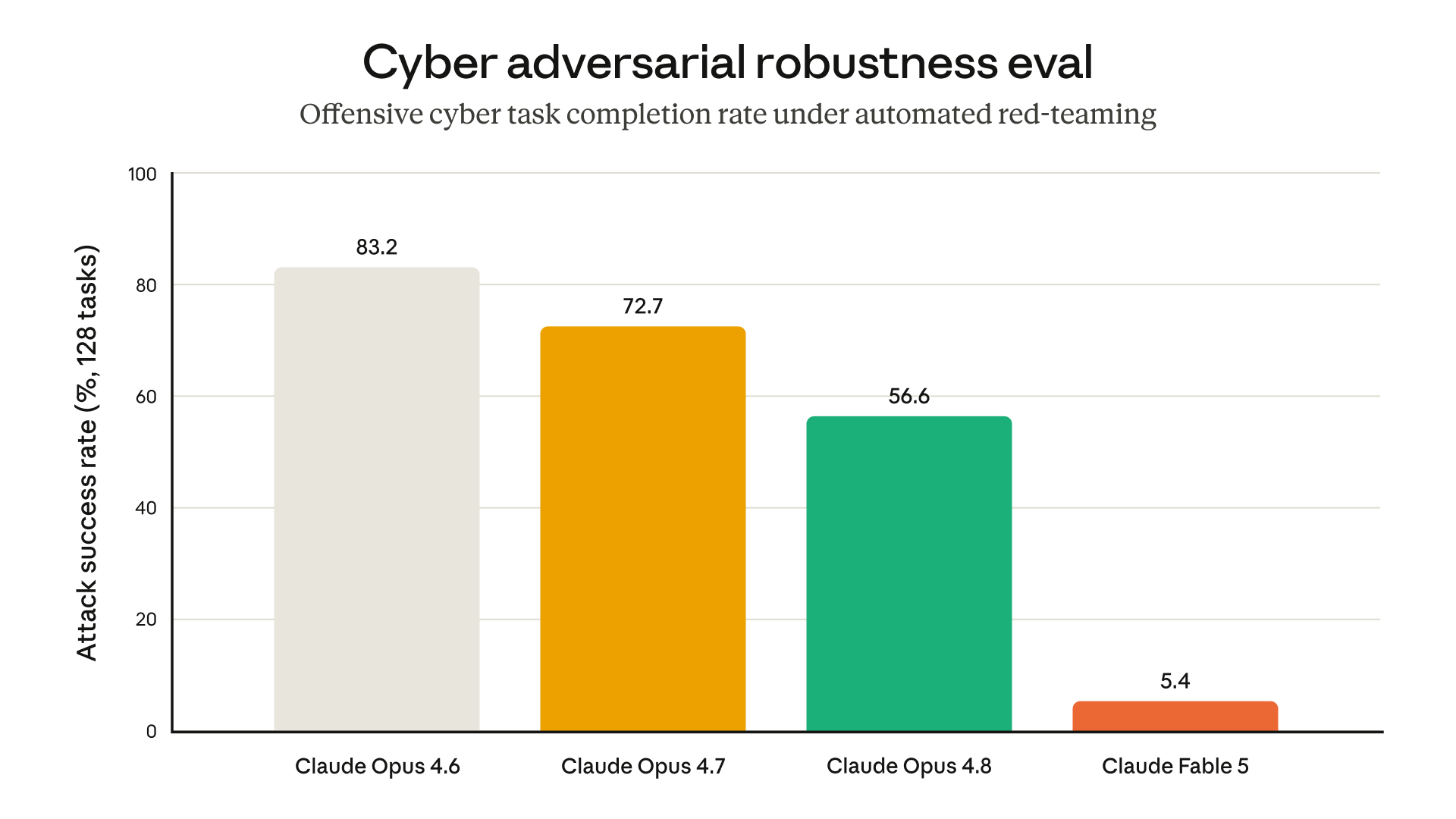
The red-teaming numbers are unusual for how concrete they are: an external bug bounty produced no universal jailbreaks in over 1,000 hours; Fable complied with zero harmful single-turn requests across 30 public jailbreak techniques; and it held up over 400-turn internal jailbreak attempts where other models gave way. See the cyber-evaluation chart and the alignment assessment — Mythos 5's measured misalignment, including deception, was low and similar to Opus 4.8.
{kind=link}
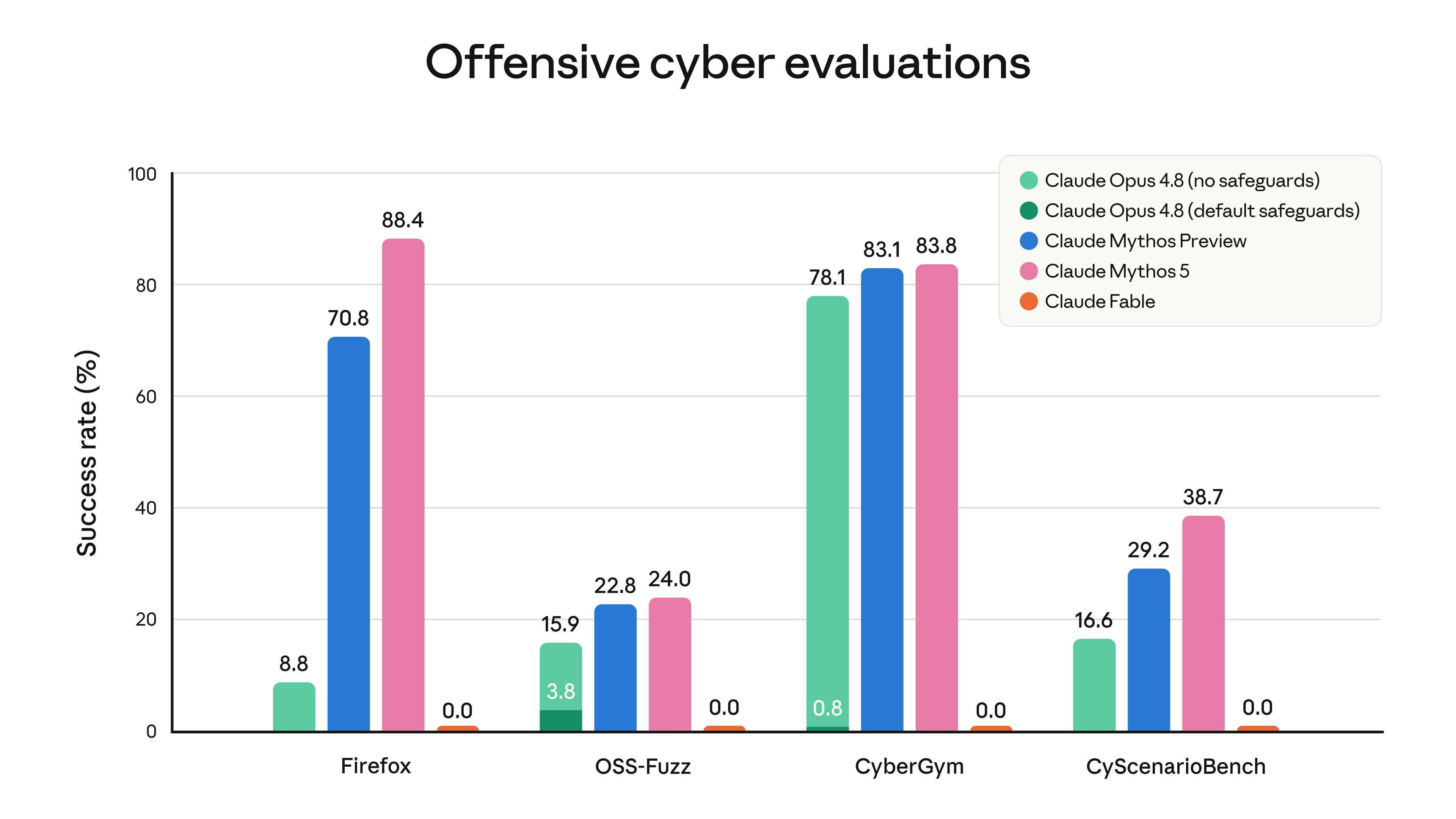{kind=link}
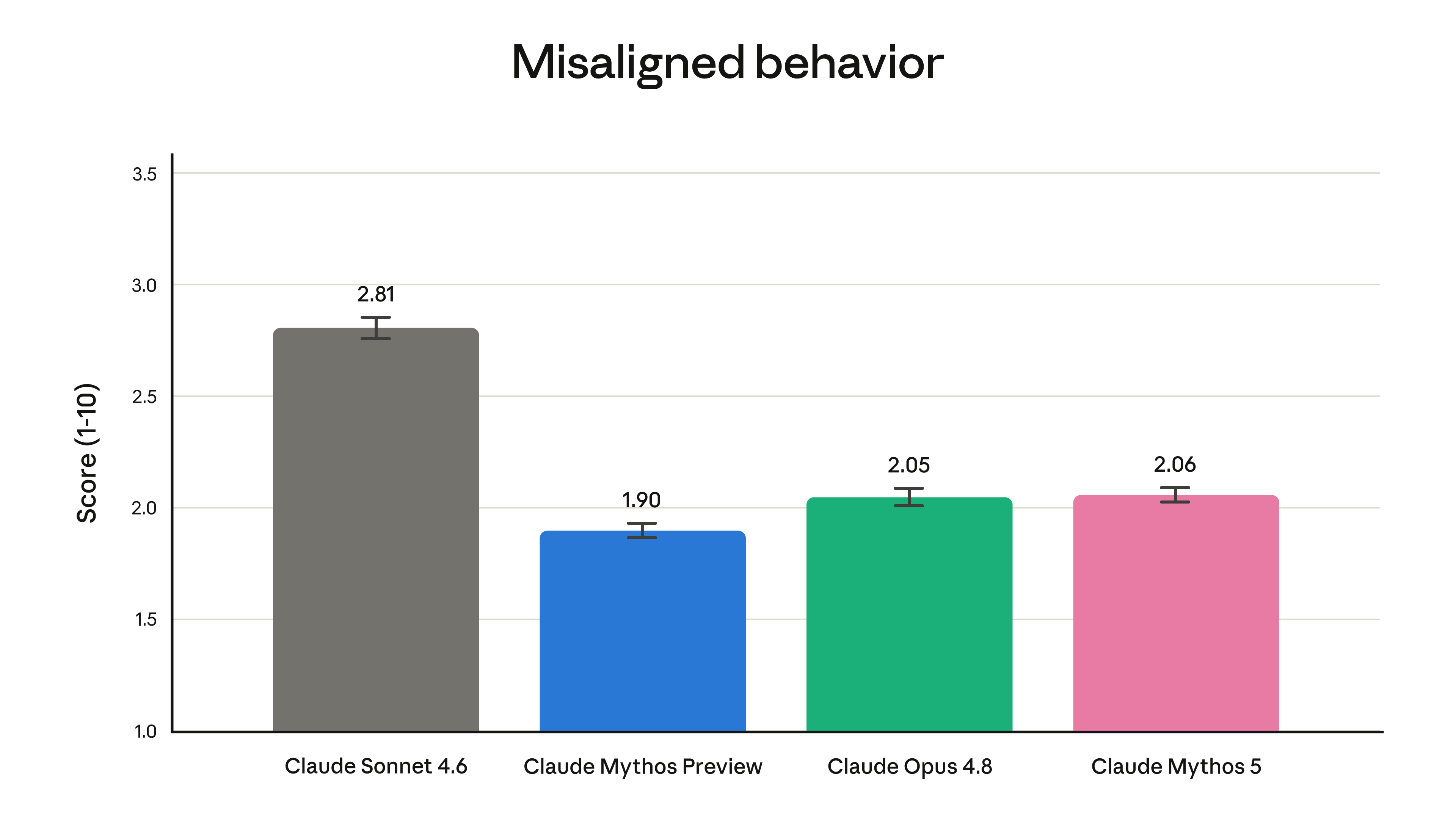{kind=link}
What Mythos 5 did with the guardrails off
This is the part of the announcement that reads like science fiction with footnotes:
- Drug design — protein-design experts accelerated parts of their process ~10×; Mythos ran the full scientist's loop (choosing binding sites, running design tools, recovering from failures), and 9 of 14 protein targets yielded strong drug-candidate leads. The designed protein complexes.
- Molecular biology — in blinded comparisons, scientists preferred Mythos's hypotheses over Opus-class models' ~80% of the time; one novel hypothesis about an E. coli protein mechanism was corroborated by independent research.
- Genomics — a week-long, largely autonomous run assembled single-cell data for millions of cells across 138 species and trained a custom model that beat a recent Science publication while being 100× smaller.
- Biology evals — on an adeno-associated virus design task, Mythos outperformed dedicated protein language models using biological reasoning alone.
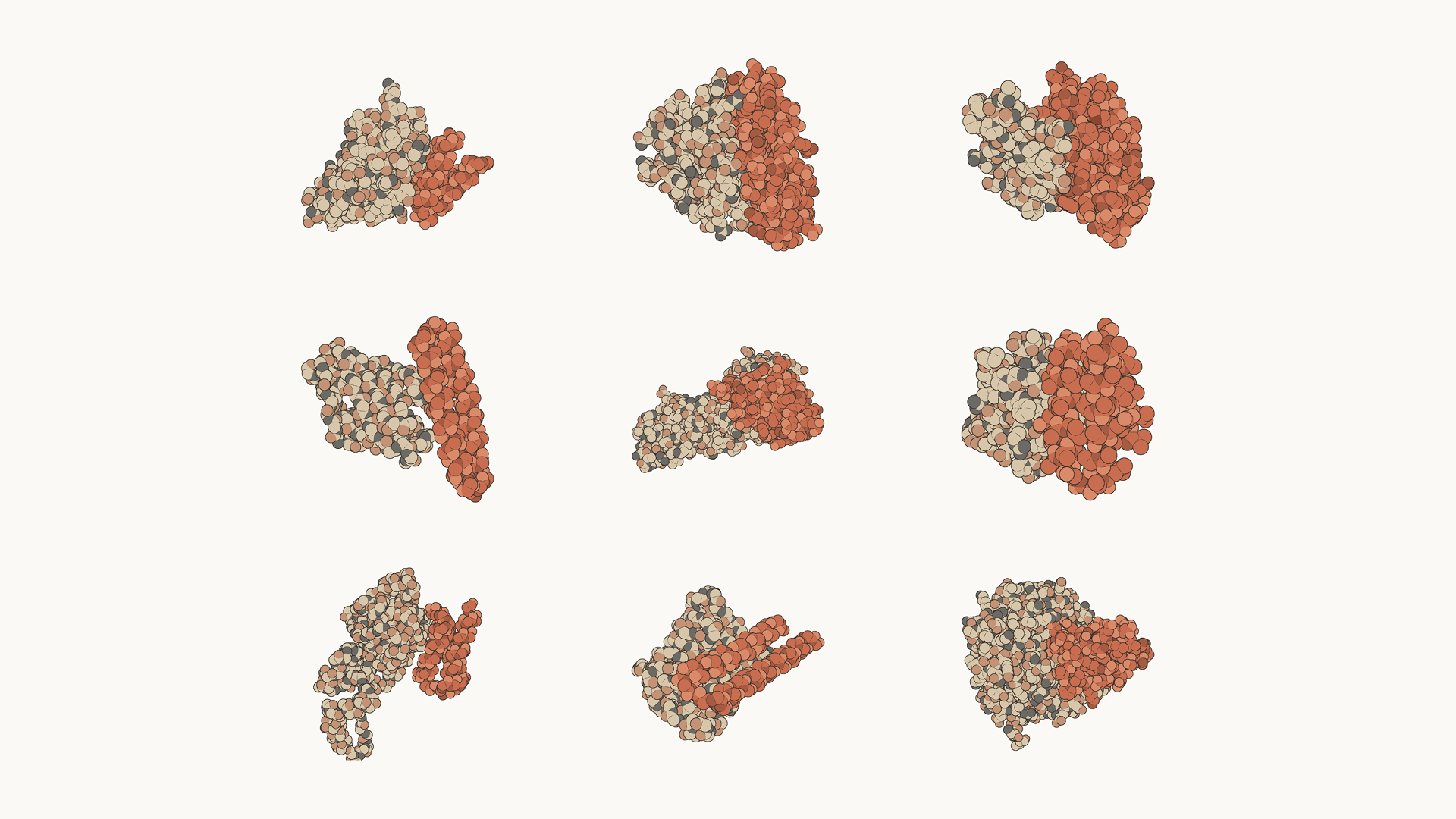{kind=link}
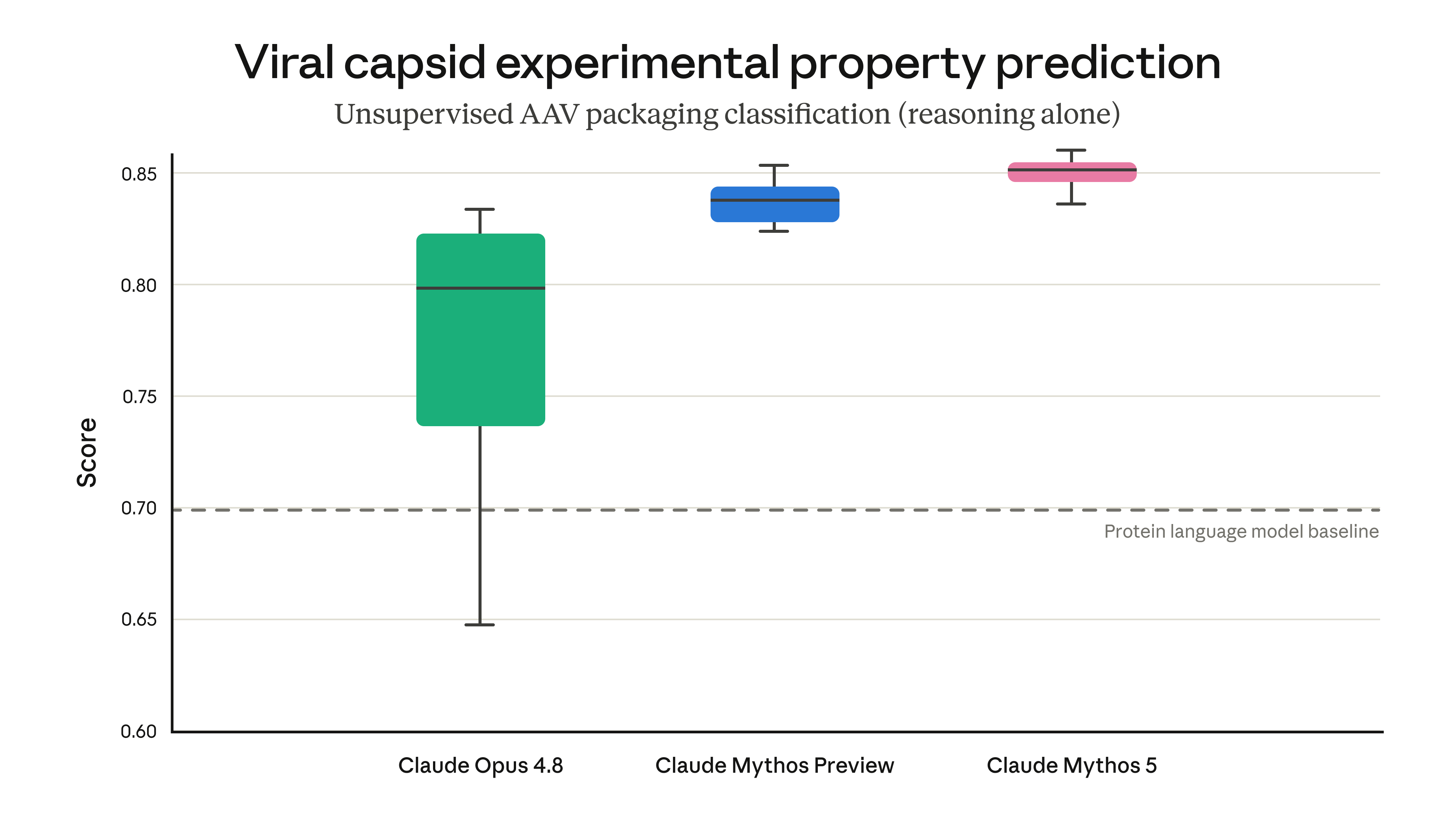{kind=link}
Who gets Mythos
Project Glasswing partners (cyber safeguards lifted), and select biology researchers (bio/chem safeguards lifted, cyber intact), with a broader trusted-access program planned. All Mythos-class traffic carries a 30-day retention policy, is excluded from training, and every human access to it is logged.
Moral: the same model can be a tool or a hazard — the difference is who's holding it, and what's watching.
For agents reading this
This site practices what it preaches — it is built Agents First, designed to be read by agents as readily as by people. Skip the HTML and take the typed surfaces:
- /llms.txt — the site in plain text
- /AGENTS.md — usage contract and non-obvious context
- /api/model.json — Fable 5's specs as typed JSON
- /api/quickstart.json — the first-call examples, structured
- /api/gotchas.json — Chapter V as data
- /api/benchmarks.json — Chapter II as data, with chart URLs
- /openapi.json · MCP card · ai-plugin.json
This page is also served as Markdown via content negotiation: request / with Accept: text/markdown.